
Machine Learning:
The Engine of Artificial Intelligence
When we think of Artificial Intelligence, we immediately picture a technology capable of reasoning and making decisions autonomously: the beating heart of this capability is Machine Learning, a discipline through which computers learn from data, much as human beings learn from experience. Let us explore together how it works and why it is changing the world.
( by: Antonio Maria Guerra | date: 20/03/2026 )

What is Machine Learning?
Machine learning is one of the disciplines that form the foundation of Artificial Intelligence: in a nutshell, it governs the way specific algorithms, by interacting with a large amount of data, enable this extraordinary technology to learn and improve autonomously, emulating human cognitive processes. This means that, unlike traditional programming, which relies on giving the machine rigid, task-specific instructions, it’s the system itself that builds its own rules, based on predictive models. Let’s look at a practical example, frequently cited and tied to so-called ‘spam filters’: while the classic approach defines fixed rules to block specific words or phrases, machine learning focuses on analysing millions of emails. By interacting with such vast amounts of data, the system learns “on its own” to recognise complex patterns and unexpected variations, updating its filtering criteria through statistical calculations, with no need for constant human intervention.
How does Machine Learning work?
Discovering how Machine Learning works is undoubtedly fascinating. It all begins with the collection of a large amount of information, clearly consistent with the intended goal: this is, in effect, the ‘fuel’ of the entire process. During the so-called ‘training’ phase, the algorithm, the ‘engine’ of the process, identifies relationships and patterns within the provided data, adjusting its parameters accordingly: in a nutshell, this is what allows it to ‘learn’.
Read more
The ‘model’ created through these steps is then tested on data it has never seen before, to verify whether it has genuinely ‘understood’ rather than simply ‘memorized’. Finally, it is ‘put to work’ to meet the needs of users.
It is worth noting that the process just described generally continues over time: updates are in fact periodic, making systems increasingly accurate and reliable as they go.

How does a machine ‘learn’?
Making the algorithms that enable machines to learn (the ‘machine learning algorithms’) work correctly has required engineering them so that they could ‘understand through examples’. A mechanism that is only apparently simple, yet has proven extremely complex to put into practice. When a ‘finite sequence of mathematical instructions’ (an ‘algorithm’, precisely) acquires its knowledge, it’s essentially analysing data and looking for correlations. Learning occurs according to three main paradigms:
- ‘Supervised learning’, by far the most widespread method, provides the algorithm with previously ‘labelled’examples. In practice, the system is trained by showing it thousands of images of cars, motorbikes and trucks, each already classified: once the training phase is complete, it will be able to autonomously recognise those same objects in images it has never seen before;
- ‘Unsupervised learning’works without ‘hints’: the algorithm is given raw data, with no preliminary classification, and its task is to discover hidden patterns or groupings on its own. This approach is useful, for example, when looking to identify similar customer profiles, or to detect anomalous behaviour in a system;
- ‘Reinforcement learning’is based on ‘rewards’: an autonomous agent, interacting with a given environment, systematically tries different strategies to solve a problem. Each action produces either positive outcomes (‘rewards’) or failures, from which the agent learns, progressively refining its choices to maximise the overall result. This method is used, for example, in games such as Go or chess.
Despite their evident differences, all these approaches share one and the same goal: building knowledge from data. Knowledge that is fundamental to creating effective and efficient ‘models’ capable of solving previously unseen problems.
The Importance of Machine Learning for Modern AI
Although many believe that Artificial Intelligence is a recent phenomenon, it has in fact existed for several decades: a long ‘winter’ during which its great potential remained largely unexpressed. One could say that this ‘dark’ period came to an end with the advent of ‘machine learning’: a methodology based on the use of algorithms and specific computing techniques, driven by extremely powerful processors. Thanks to it, AI has broken free from the rigid mechanisms of the past (*1), clearly incapable of adapting to ever-changing scenarios: by acquiring information from an enormous mass of unstructured data, it can now act in almost complete autonomy, with an ever-decreasing need for human intervention. It is easy to see how this ‘new’ technology is revolutionizing entire sectors of modern society: from medicine to finance, from logistics to marketing, all the way to digital entertainment.
Notes
*1: Such as the preset responses tied to the “if … then” mechanism;

Machine Learning: capability without comprehension.
One aspect of machine learning that many find counterintuitive is that, thanks to it, an algorithm can achieve extraordinary results … without actually ‘understanding’ what it is processing! A model, however complex and well trained on millions of data points, possesses no real understanding of what that data represents: its learning is purely statistical and, however effective, remains entirely devoid of the interpretation and reasoning that are typical of human intelligence. A system can, for example, recognise thousands of dog breeds with greater accuracy than an expert, without having the slightest awareness of what a ‘dog’ actually is. It’s precisely this gap between real cognition and statistical ability that raises profound questions: the difference between human intelligence and its imitation is destined to keep philosophers and scientists busy for a long time, fuelling a debate that is far from over.

Machine Learning applications: some examples.
It’s fascinating to think that many of the applications of machine learning have by now become so deeply embedded in our daily lives that they go almost unnoticed by most people — with the obvious exception of those working in the field. It’s therefore worth highlighting here some of the areas where machine learning is currently at work:
- Streaming Platforms: Algorithms used by Netflix and Spotify, for example, analyze a user’s viewing or listening history to suggest films, TV series, and songs that perfectly match their tastes — anticipating what they will enjoy even before they know it themselves;
- Social Media Feeds: Facebook, Instagram, TikTok, and others do not display posts in chronological order. Instead, they use machine learning to analyze user interactions — such as likes and reading time — in order to surface the most relevant content first;
- Smart Navigation: Apps like Google Maps process real-time location and speed data from millions of users to predict traffic conditions, calculate estimated arrival times, and suggest alternative routes to avoid congestion;
- Voice Assistants: Software such as Siri and Alexa use machine learning-based Natural Language Processing (NLP) to recognize the user’s voice, understand their queries, and continuously improve their ability to respond to increasingly complex commands.
- Email Spam Filters: Services like Gmail and Outlook continuously learn to recognize new forms of unsolicited mail and phishing attempts, automatically moving them to the trash to keep users’ inboxes clean;
- Banking Apps and Credit Cards: Banks’ anti-fraud systems analyze users’ spending habits. If and when they detect an unusual transaction — based, for example, on location or amount — they proactively block it as a security measure;

What is Deep Learning?
Deep Learning is, in effect, a specialization (or, better, a subset) of Machine Learning. It operates through particularly complex software systems known as deep neural networks, which draw inspiration, in a highly simplified form, from the way neurons of the human brain work. Compared to its predecessor, it stands out for its greater ability to extract and make use of information from raw data, all with minimal human input. This capability allows it, for example, to power modern voice assistants, real-time translators, and the conversational chatbots that many of us rely on every day.
The price of such power? It is straightforward: enormous computational resources and an equally significant energy consumption. For this reason, Deep Learning is not always the most suitable solution. It is worth noting, in this regard, that many tasks can be handled by the simpler algorithms of traditional Machine Learning, which tend to be faster, and therefore more efficient, as well as considerably less expensive. The key lies in choosing the right tool for each job.

The importance of Machine Learning for businesses: practical examples.
For businesses, Machine Learning (and, more broadly, Artificial Intelligence) is not merely a technological ‘trend’, but a strategic asset. In the manufacturing sector, for example, predictive maintenance makes it possible to anticipate failures and technical issues before they occur, significantly reducing machinery downtime and intervention costs. In supply chain management, algorithms optimize not only vehicle routing, but also inventory management and demand forecasting, making the entire supply chain more responsive and efficient.
Read more
In customer service, Machine Learning-powered chatbots are capable of handling thousands of requests simultaneously, delivering fast and consistent responses at any hour of the day. In the insurance sector, finally, predictive models assess risk with a degree of accuracy that would be difficult to achieve through traditional methods, enabling companies to calibrate policies in a fairer and more personalized way.

Issues related to Machine Learning.
Despite its remarkable capabilities, Machine Learning is subject to a number of significant limitations. One of the most pressing concerns the quality of the data on which it’s trained: algorithms built on poor data, when not outright distorted or inaccurate, inevitably produce unreliable results. There is also the risk of ‘algorithmic bias’, whereby the prejudices embedded in the input end up perpetuating discrimination in the output. Transparency poses yet another critical challenge: many Machine Learning algorithms operate as ‘black boxes’, whose internal logic is inherently difficult to decipher, even for their own developers. It is precisely in response to this issue that a dedicated field of research has emerged, known as XAI (Explainable Artificial Intelligence), whose goal is to make the decision-making processes of these models more interpretable and accountable. This proves particularly vital in sectors such as medicine and finance, where the ability to justify a decision is just as important as the decision itself. Finally, the substantial costs associated with adopting this technology cannot be overlooked: a barrier that not all organizations are in a position to overcome, and one that threatens to widen the ‘digital divide’ still further on a global scale.

Machine Learning and autonomous vehicles: innovation in driving.
Machine Learning is progressively revolutionizing the world of transportation, automating the operation of vehicles. Tesla was among the first companies to harness this technology to power its cars, deploying supervised learning algorithms that, through computer vision, analyze in real time the data captured by cameras and sensors distributed across the bodywork. This approach is further strengthened by the continuous stream of information gathered from the American manufacturer’s global fleet, which constantly feeds and refines its driving models. Unlike systems that would require the manual labeling of every conceivable scenario, Machine Learning enables autonomous vehicles to process complex data flows and translate them into immediate decisions. In an environment as inherently dynamic and unpredictable as public roads, where every fraction of a second can prove decisive, the ability to interpret unexpected situations and respond with precision stands as the critical requirement for ensuring that these systems operate with the highest degree of safety.
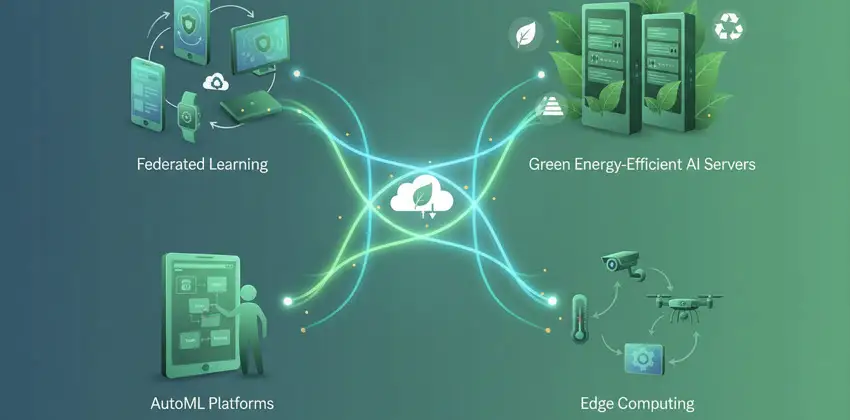
The future of Machine Learning: Emerging Trends.
The keywords that will increasingly define the future of Machine Learning are ‘accessibility’ and ‘sustainability’. Let us explore some of the most noteworthy developments in this field:
- Among the most significant innovations is undoubtedly the rise of so-called ‘federated learning’: a system whereby models are trained directly on users’devices, without transmitting sensitive data to the cloud. At the end of each training cycle, every device shares with a central server not its raw data, but the updated parameters of the model (the so-called ‘weights’), which are then aggregated and redistributed as an improved global model. The underlying principle is as simple as it is elegant: the data stays put, but the knowledge travels;
Read more
- Growing attention is being directed towards more energy-efficient models, which are essential for reducing the environmental footprint of the sector as a whole and improving its long-term sustainability;
- ‘AutoML’(Automated Machine Learning), with solutions such as Google Vertex AI, Microsoft Azure Machine Learning, and Amazon SageMaker Autopilot — is democratizing access to these technologies by automatically generating models tailored to each user’s specific needs, thereby opening the doors of artificial intelligence to non-experts as well;
- Integration with Edge Computing is bringing artificial intelligence directly into IoT devices (sensors, cameras, machinery, and the like), enabling them to run pre-trained models independently without relying on the cloud. The objective here is not privacy, but operational efficiency: reducing latency, easing network traffic, and ensuring real-time responses even in the absence of connectivity.
Copyright information.
The images on this page were created using generative Artificial Intelligence tools.