
Machine Learning:
Il Motore dell’Intelligenza Artificiale
Quando si pensa all’Intelligenza Artificiale, viene subito in mente una tecnologia capace di ragionare e prendere decisioni in autonomia: ebbene, il cuore pulsante di tale capacità è il Machine Learning, disciplina grazie alla quale i computer imparano dai dati, alla stregua di un essere umano che apprende dall’esperienza. Scopriamo insieme come funziona e perché sta cambiando il mondo.
( di: Antonio Maria Guerra | data: 20/03/2026 )

Cos’è il Machine Learning?
Il Machine Learning è una delle discipline che stanno alla base del funzionamento dell’Intelligenza Artificiale: in sostanza, regola il modo in cui specifici algoritmi, interagendo con una grande mole di dati, danno modo a questa straordinaria tecnologia di apprendere e migliorare in modo autonomo, emulando i processi cognitivi umani. Ciò significa che, a differenza della programmazione tradizionale, basata sull’impartire alla macchina istruzioni rigide e specifiche per ogni compito, è il sistema stesso a crearsi le proprie regole, basandosi su modelli predittivi.
Facciamo un esempio pratico, spesso citato e legato ai cosiddetti ‘filtri antispam’: mentre l’approccio classico definisce regole fisse per bloccare singole parole o locuzioni, il machine learning punta sull’analisi di milioni di email. Interagendo con così tanti dati, il sistema impara ‘da solo’ a riconoscere schemi complessi e variazioni impreviste, aggiornando i propri criteri di blocco grazie a calcoli statistici, senza bisogno di un continuo intervento umano.
Come funziona il Machine Learning?
Scoprire il funzionamento del Machine Learning è indubbiamente affascinante. Tutto comincia con la raccolta di una grande mole di informazioni, ovviamente coerenti con l’obiettivo prefissato: questi sono, di fatto, il ‘carburante’ dell’intero processo. Durante il cosiddetto ‘addestramento’, l’algoritmo, ovvero il ‘motore’ del processo, identifica relazioni e pattern all’interno delle nozioni fornite, regolando di conseguenza i propri parametri: in sostanza ciò gli dà modo di ‘imparare’.
Continua
Il ‘modello’ creato grazie a questi passaggi viene quindi testato su dati che non ha mai visto prima, per verificare se ha effettivamente ‘compreso’ e non solo ‘memorizzato’. Infine, è ‘messo a lavoro’ per rispondere alle esigenze dell’utenza.
È importante evidenziare che il processo appena descritto, generalmente, prosegue nel tempo: gli aggiornamenti sono infatti periodici, così da rendere i sistemi sempre più precisi e affidabili nel tempo.

Come ‘apprende’ una macchina?
Far funzionare correttamente gli algoritmi che danno modo alle macchine di imparare (i ‘machine learning algorithms’) ha implicato l’ingegnarsi affinché questi ‘capissero attraverso esempi’. Un meccanismo solo apparentemente semplice, che è stato estremamente complesso mettere in pratica. Quando una ‘sequenza finita di istruzioni matematiche’ (un ‘algoritmo’, appunto) acquisisce la sua conoscenza, in sostanza sta analizzando dati, cercando correlazioni. L’apprendimento avviene secondo tre principali paradigmi:
- Il ‘supervised learning’, metodo senza dubbio maggiormente diffuso, fornisce all’algoritmo esempi precedentemente ‘etichettati’. In pratica, si addestra il sistema mostrandogli migliaia di immagini di auto, moto e camion, ciascuna già classificata: una volta completato l’addestramento, sarà in grado di riconoscere autonomamente quegli stessi oggetti in immagini che non ha mai visto;
- L’ ‘unsupervised learning’ funziona invece senza ‘suggerimenti’: all’algoritmo vengono forniti dati grezzi, senza alcuna classificazione preliminare, e il suo compito è scoprire da solo eventuali schemi o raggruppamenti nascosti. È un approccio utile, ad esempio, quando si vogliono identificare profili di clientela simili tra loro, o individuare comportamenti anomali in un sistema;
- Il ‘reinforcement learning’ si basa sulle ‘ricompense’: un agente autonomo, interagendo con un dato ambiente, prova sistematicamente diverse strategie per risolvere un problema. Ogni azione produce risultati positivi (‘ricompense’) o fallimenti, dai quali l’agente impara, affinando nel tempo le proprie scelte per massimizzare il risultato complessivo. Questo metodo è utilizzato, ad esempio, nei giochi come Go o gli scacchi.
Nonostante le evidenti differenze, tutti questi approcci condividono un medesimo fine, ovvero costruire conoscenza dai dati. Una conoscenza fondamentale per dar vita a ‘modelli’ efficaci ed efficienti cui demandare la risoluzione di problemi inediti.
L’importanza del Machine Learning per l’IA moderna.
Sebbene molti pensino che l’Intelligenza Artificiale sia una ‘diavoleria’ dei giorni nostri, in realtà esiste da parecchi decenni: un lungo ‘inverno’ in cui le sue grandi potenzialità sono rimaste perlopiù inespresse. Si può dire che questo periodo ‘buio’ sia terminato con l’avvento del ‘machine learning’: una metodologia basata sull’uso di algoritmi e particolari tecniche informatiche, spinta da processori estremamente potenti. Grazie ad essa l’IA si è liberata dai rigidi meccanismi del passato (*1), chiaramente incapaci di adattarsi a scenari in continua evoluzione: acquisendo informazioni da un’enorme massa di dati indifferenziati, ora può agire in quasi completa autonomia, con un intervento umano sempre più ridotto.
Facile comprendere che questa ‘nuova’ tecnologia stia rivoluzionando interi settori della società moderna: dalla medicina alla finanza, dalla logistica al marketing, fino all’intrattenimento digitale.
Note
*1: Come le risposte prefissate legate al meccanismo “se … allora” (“if … then”);

Machine Learning: quando l’apprendimento non equivale alla comprensione.
Un aspetto del machine learning che a molti risulta controintuitivo è che, grazie ad esso, un algoritmo può raggiungere risultati straordinari … senza peraltro ‘capire’ realmente ciò che sta elaborando! Un modello, per quanto complesso e ben addestrato su milioni di dati, non possiede infatti alcuna reale comprensione di ciò che questi rappresentano: il suo è un apprendimento puramente statistico che, per quanto efficace, è tuttavia del tutto privo dell’interpretazione e del ragionamento tipici dell’intelligenza umana. Un sistema può, ad esempio, riconoscere migliaia di razze di cani con precisione superiore a un esperto, senza avere la minima consapevolezza di cosa sia effettivamente un ‘cane’. È proprio questo divario tra cognizione reale e ‘abilità statistica’ a sollevare interrogativi profondi: la differenza tra l’intelligenza umana e la sua imitazione occuperà a lungo filosofi e scienziati, alimentando un dibattito destinato a restare aperto.

Le applicazioni del Machine Learning: alcuni esempi.
È affascinante pensare che molte tra le applicazioni del Machine Learning siano ormai talmente integrate nella nostra quotidianità da passare quasi inosservate alla maggior parte delle persone, con l’eccezione, ovviamente, degli ‘addetti ai lavori’.
E’ dunque il caso, in questa sede, di evidenziare alcuni degli ambiti nei quali è attualmente all’opera:
Piattaforme di Streaming: Gli algoritmi di Netflix e Spotify (ad esempio), analizzano la cronologia di visione o ascolto dell’utente per suggerire film, serie TV e brani musicali perfettamente in linea con i suoi gusti, prevedendo cosa gli piacerà ancor prima che l’utente stesso lo sappia;
Feed dei Social Media: Facebook, Instagram, TikTok, etc. non mostrano i post in ordine cronologico, ma utilizzano il machine learning per analizzare le interazioni dell’utente (like, tempo di lettura, etc.), così da proporgli per primi i contenuti ritenuti più rilevanti;
Navigazione Intelligente: App come Google Maps elaborano in tempo reale i dati sulla posizione e sulla velocità di milioni di utenti per prevedere le condizioni del traffico, calcolare l’orario di arrivo stimato e suggerire percorsi alternativi così da evitare ingorghi;
Assistenti Vocali: Software come Siri ed Alexa utilizzano l’elaborazione del linguaggio naturale (NLP) basata sul machine learning per riconoscere la voce dell’utente, comprenderne le domande e migliorare la capacità di risposta a comandi sempre più complessi;
Filtri Email Antispam: Servizi come Gmail o Outlook imparano continuamente a riconoscere nuove forme di posta indesiderata o tentativi di phishing, spostandoli automaticamente nel cestino per mantenere pulita la posta in arrive degli utenti;
App Bancarie e Carte di Credito: I sistemi antifrode delle banche analizzano le abitudini di spesa dell’utente. Se e quando rilevano una transazione anomala (basandosi, ad esempio, su luogo o importo) la bloccano preventivamente per sicurezza;

Deep Learning: il Machine Learning profondo.
Il Deep Learning è, di fatto, una specializzazione (o, meglio, un sottoinsieme) del Machine Learning. Il suo funzionamento è basato su software particolarmente complessi, le reti neurali profonde, che si ispirano, in forma molto semplificata, al modo in cui lavorano i neuroni del cervello umano. Rispetto al suo predecessore, si distingue per una maggiore capacità di estrarre informazioni dai dati grezzi e di farne uso, il tutto con un contributo umano molto ridotto.
Questa capacità gli consente, ad esempio, di alimentare i moderni assistenti vocali, i traduttori istantanei e i chatbot conversazionali che ognuno di noi utilizza quotidianamente.
Il prezzo di così tanta potenza? È presto detto: enormi risorse computazionali e un consumo energetico altrettanto elevato. Per questa ragione, il Deep Learning non rappresenta sempre la soluzione ottimale. Vale la pena sottolineare, a tal proposito, che molte esigenze possono essere gestite dai più semplici algoritmi del Machine Learning tradizionale, che risultano più rapidi, e quindi più efficienti, oltre che meno costosi. La chiave è scegliere lo strumento giusto per ogni compito.

L’importanza del Machine Learning per le aziende: esempi pratici.
Per le aziende, il Machine Learning (e, più in generale, l’Intelligenza Artificiale) non è solo una ‘moda tecnologica’, ma un asset strategico. Nel settore manifatturiero, ad esempio, la manutenzione predittiva consente di anticipare guasti e problematiche tecniche prima che si verifichino, riducendo significativamente i tempi di inattività dei macchinari e i costi di intervento. Nella supply chain, gli algoritmi ottimizzano non solo il routing dei veicoli, ma anche la gestione delle scorte e la previsione della domanda, rendendo l’intera catena di approvvigionamento più reattiva ed efficiente.
Continua
Nel customer service, i chatbot alimentati dal Machine Learning sono in grado di gestire migliaia di richieste simultaneamente, garantendo risposte rapide e coerenti a qualsiasi ora del giorno. Nel settore assicurativo, infine, i modelli predittivi valutano il rischio con una precisione difficilmente raggiungibile con i metodi tradizionali, consentendo alle compagnie di calibrare le polizze in modo più equo e personalizzato.

Le problematiche legate al Machine Learning.
Nonostante la sua straordinaria potenza, il Machine Learning è soggetto a diverse problematiche. Una tra le principali è senza dubbio legata alla qualità delle informazioni su cui viene addestrato: algoritmi costruiti su dati scadenti, quando non addirittura distorti o errati, producono infatti risultati altrettanto inaffidabili. Esiste inoltre il pericolo del ‘bias algoritmico’, per cui i pregiudizi presenti negli input finiscono per perpetuare discriminazioni negli output. La trasparenza rappresenta un’ulteriore questione critica: molti algoritmi di Machine Learning operano come ‘scatole nere’ (‘black boxes’), la cui logica interna è spesso incomprensibile per sua natura, persino agli occhi dei rispettivi creatori. Non a caso, proprio in risposta a questa sfida, si è sviluppato un campo di ricerca dedicato noto come XAI (Explainable Artificial Intelligence), il cui obiettivo è rendere i processi decisionali dei modelli più trasparenti e interpretabili. Ciò risulta di fondamentale importanza soprattutto in settori come la medicina e la finanza, nei quali la capacità di spiegare una decisione è tanto cruciale quanto la decisione stessa. Infine, non si possono trascurare gli ingenti costi legati all’adozione di questa tecnologia: un ostacolo che non tutte le realtà sono in grado di superare e che rischia di amplificare ulteriormente il ‘divario digitale’ (‘digital divide’) a livello globale.

Machine Learning e veicoli autonomi: l’innovazione nella guida.
Il Machine Learning sta progressivamente rivoluzionando il mondo dei trasporti, automatizzando la conduzione dei veicoli. Tesla è stata tra le prime aziende a sfruttare questa tecnologia per far muovere i propri mezzi, impiegando algoritmi basati sull’apprendimento supervisionato che, grazie alla computer vision, analizzano in tempo reale i dati provenienti dalle telecamere e dai sensori disseminati sulla carrozzeria. Questo approccio è potenziato dal costante flusso di informazioni raccolte dalla flotta globale del produttore americano, che alimenta e affina continuamente i modelli di guida. A differenza di sistemi che richiederebbero una catalogazione manuale di ogni scenario possibile, il Machine Learning consente ai veicoli a guida autonoma di elaborare flussi di dati complessi e di tradurli in decisioni immediate. In un contesto come quello stradale, altamente dinamico e imprevedibile, dove ogni frazione di secondo può rivelarsi cruciale, la capacità di interpretare situazioni inattese e rispondere con prontezza rappresenta il requisito fondamentale per garantire che questi sistemi operino in piena sicurezza.
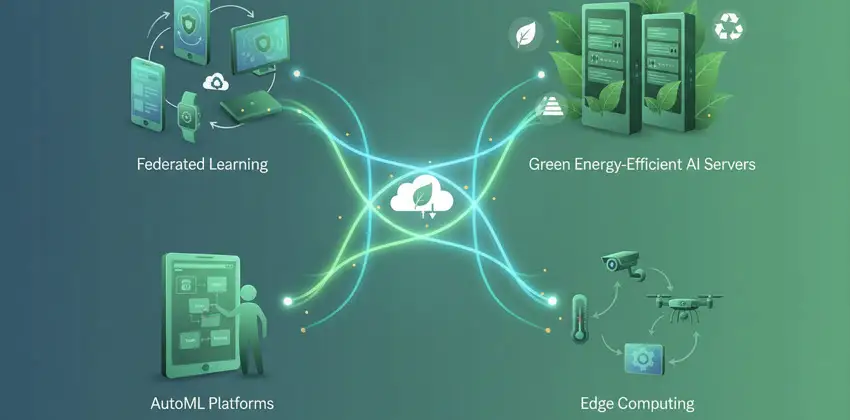
Il futuro del Machine Learning: le tendenze emergenti.
Le parole d’ordine che sempre più caratterizzeranno il futuro del Machine Learning sono ‘accessibilità’ e ‘sostenibilità’. Scopriamo alcune tra le novità più rilevanti di questo campo:
- Tra le innovazioni più significative spicca senza dubbio l’ascesa del cosiddetto ‘federated learning’: un sistema grazie al quale i modelli vengono addestrati direttamente sui dispositivi degli utenti, senza inviare dati sensibili nel cloud. Al termine di ogni ciclo di addestramento, ciascun dispositivo condivide con un server centrale non i propri dati, bensì i parametri aggiornati del modello (i cosiddetti ‘pesi’), che vengono aggregati e ridistribuiti come modello globale migliorato. Il principio di fondo è tanto semplice quanto elegante: i dati non si muovono, ma la conoscenza sì;
Continua
- Cresce l’attenzione verso modelli più efficienti dal punto di vista energetico, fondamentali per ridurre l’impronta ecologica dell’intero settore e migliorarne la sostenibilità ambientale;
- L’ ‘AutoML’(Automated Machine Learning), con soluzioni come Google Vertex AI, Microsoft Azure Machine Learning e Amazon SageMaker Autopilot, sta democratizzando l’accesso a queste tecnologie, generando in automatico modelli su misura per le esigenze di ciascun utente e aprendo così le porte dell’Intelligenza Artificiale anche ai non esperti;
- L’integrazione con l’Edge Computing sta portando l’Intelligenza Artificiale direttamente all’interno dei dispositivi IoT (sensori, telecamere, macchinari e simili), consentendo loro di eseguire in autonomia modelli già addestrati senza dover ricorrere al cloud. L’obiettivo, in questo caso, non è la privacy bensì l’efficienza operativa: ridurre la latenza, alleggerire il traffico di rete e garantire risposte in tempo reale anche in assenza di connettività.
Copyright information.
The images on this page were created using generative Artificial Intelligence tools.